This post was written by Hannah Wang, Senior Digital Preservation Specialist.
The NARA Digital Preservation Unit is very excited to announce that the most recent release of the Digital Preservation Framework is now available on GitHub. This release includes a major overhaul of the Risk Matrix, with new and updated questions about how we evaluate risk to file formats, as well as a new report on the file format extensions present in our holdings.
This blog post is the second in a four-part series about this major re-release. In the first post, I introduced the Framework and its three main components. In this post, I’ll discuss what exactly has changed in this release. The third post will get into the nitty-gritty of our process for revising the Risk Matrix. The final post will discuss some interesting findings and takeaways from this whole process.
We were lucky to work with the Public Affairs team at NARA to put together this article about the updates to the Framework; it’s a great high-level overview of this project and digital preservation at NARA. And if you want even more information about how we assess file format risk at NARA, you can check out our paper, co-written with our Library of Congress colleagues, that we presented at the International Conference on Digital Preservation in September.

What has changed and why?
The main part of the Framework that has changed is the Risk Matrix; apart from minor maintenance, nothing has changed in the File Format Preservation Action Plans and the Record Category Preservation Action Plans (for an explainer on all of these terms, see my last post).
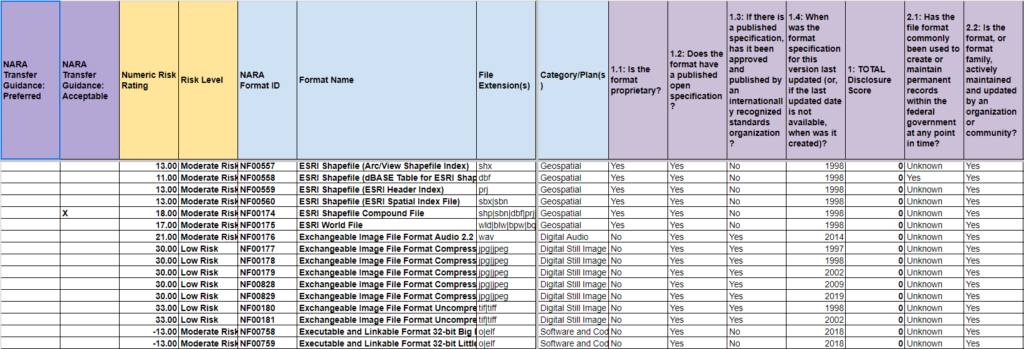
We have also released a new report of the file format extensions in our holdings – more on that in a bit.
So, what’s changed in the Risk Matrix with this big re-release, and why did we make these changes?
More concise!
The old Risk Matrix had a total of 39 questions across 9 categories (not including the Prioritization questions concerning the number of files in our holdings and our ability to transform them). For staff adding and updating formats in the Risk Matrix, the sheer length of the exercise can be daunting, and it can be frustrating if there are multiple questions that seem to be asking the same thing.
One of the questions that we asked ourselves when we updated the Risk Matrix was, “Are there places where we can be more concise and merge similar questions to make the task of risk assessment more streamlined?” The answer was yes!
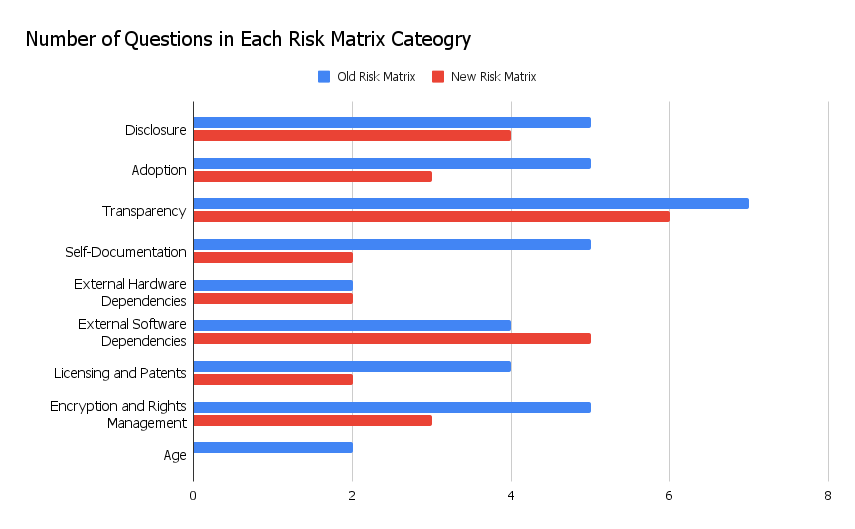
The new version of the Risk Matrix has just 27 questions across 8 categories. We removed the “Age” category of questions because we were able to merge the two age-related questions (“When was the Format Specification first created?” and “When was the Format Specification last updated?”) into one question: “When was the format specification for this version last updated (or, if the last updated date is not available, when was it created)?” We ultimately determined that up-to-date maintenance of a specification is a better indicator of risk than when it was originally created. Down to one question in this category, we moved it to the Disclosure section so that it lives alongside the other questions related to the format specification’s creation and maintenance.
We removed and condensed other similar questions throughout the Risk Matrix; documentation about these changes can be found on GitHub in 2024 NARA Risk Matrix Updates.
New questions!
In addition to removing and/or merging similar questions, we added 8 new questions. These questions address additional risk factors that have emerged or become clear to the Digital Preservation Unit over the last few years. They are also highlighted in 2024 NARA Risk Matrix Updates.
An example of a new set of questions can be found in the Transparency section:
- 3.5: Does this format support declared or hidden embedded data?
- 3.6: If the format supports declared or hidden embedded data, does the format list or provide standard information about embedded data?
These questions emerged from conversations with our colleagues in various custodial units at NARA. PDF Collections or “Portfolios” are an example of a format that has posed a new preservation challenge because of the declared embedded data that could be present in these types of files, which allow the embedding or attaching of files in any format. Formats like PDF Portfolio do include standard information in their metadata about this embedded data, which helps with processing and preservation, but the potential presence of such data makes the format itself a slightly higher preservation risk.
New scoring logic and weighting!
When we would perform maintenance on the old Risk Matrix, we would notice that there were many places where scoring logic had been applied inconsistently. There were many implicit logic pathways in the Risk Matrix; for example:
- Does the format have a published open specification?
- Has the specification been approved and published by an internationally recognized standards body?
If the answer to Question #1 is “No,” how do you answer the second question? In some cases, we had answered Question #2 “N/A,” but in other cases we had answered “No.” These differences in answers would result in different numeric risk ratings. There were questions with this kind of implicit logic pathway all over the Risk Matrix, and they were all answered differently depending on who was scoring it (or even what kind of day they were having). We did not have explicit guidance about how to answer these kinds of questions.
In the new Risk Matrix, this is what these questions look like:
- Does the format have a published open specification?
- If there is a published specification, has it been approved and published by an internationally recognized standards organization?
In addition to rewording the question to make it clear that it depends on the answer to the last question, we have updated our internal SOP to explicitly say that if the answer to Question #1 is “No,” the answer to Question #2 is “N/A.”
We have also adjusted the relative “weights” assigned to each question in the Risk Matrix to reflect our current thinking about the riskiness of certain factors. Questions about external hardware dependency and current renderer availability, for example, have been given stronger weight. Current weighting is documented in Risk Matrix Weights and all changes can be found in 2024 NARA Risk Matrix Updates.

Better documentation!
In order to address some of the inconsistencies that were noted above and make our work more transparent, we have created several more pieces of collateral documentation. These include:
- A readme with information about how to view and use the Risk Matrix, as well as justifications and problem statements for each question, so that you can see why we’re asking the questions that we ask
- A comprehensive document of all the updates that were made to the Risk Matrix in this round (in addition to the changelog that we publish every quarter)
- A spreadsheet of all formats that had their Risk Level change as a result of these updates
- An appendix to our SOP with more specific guidance on how to score different categories of formats (currently internal only, but we hope to publish a public version in the coming months)
A new way to view the Risk Matrix!
One of the issues with the old Risk Matrix was that it could be difficult (or impossible) for a user to assign meaning to a numeric value that had been entered in the Matrix. For example, if you look at the “Impact of Patents” section for the CorelDraw Drawing 8.0 format (NF00147), you would see that both questions received negative scores:
| NARA Format ID | Format Name | File Extension(s) | 7.1: Is the format subject to patent claims that may impede the development of open source tools for opening and managing the files? | 7.2: Does the format have open source license terms? |
| NF00147 | CorelDraw Drawing 8.0 | cdr | -2 | -2 |
But if you look at the Risk Matrix Weights spreadsheet, you’ll see that for Question 7.1, a -2 could translate to either a “Yes” or “Unknown,” and for Question 7.2, a “-2” could translate to either a “No” or “Unknown.” How do you know what the actual answer is?
In the old Risk Matrix, there was no way to know, either for outside users of the Risk Matrix or for Digital Preservation Unit staff. This presented challenges both for usability and maintenance.
In the new Risk Matrix, there are two “views”: both the “old” numeral-only view, but also a new “Labeled” view. Let’s look at the “Labeled” view for this same format:
| NARA Format ID | Format Name | File Extension(s) | 7.1: Is the format subject to patent claims that may impede the development of open source tools for opening and managing the files? | 7.2: Does the format have open source license terms? |
| NF00147 | CorelDraw Drawing 8.0 | cdr | Unknown | No |
Now, you can see that a “-2” for Question 7.1 means “Unknown” and a “-2” for Question 7.2 means “No.” This makes the Risk Matrix a lot more transparent than it was before.
Behind the scenes, the “Labeled” view is used for input, and it automatically populates the “Numbered” view through formulas; this makes it much easier for the Digital Preservation Unit to understand the decisions that we have made in the Risk Matrix while reviewing our previous research.
File format extensions report
Last but not least, we have released a new report that lists the file extensions in our holdings. The extensions and corresponding file counts in the report were generated by combining reports from various preservation systems across NARA for Federal, Legislative, and Presidential electronic records.
We were driven to release this information in part by Andy Jackson’s great work on the Digital Preservation Workbench, where you can now see this data as a Collection Profile. In addition to this use case, we are hopeful that the over 37,000 format extensions in our holdings will provide potential avenues of exploration for file format researchers.
There are, of course, caveats that accompany this information. It is not an exact, up-to-date representation of every file extension and count in our electronic records holdings. File extensions themselves can be misleading as they can be manually changed in most operating systems. Not all file extensions may be clearly relatable to a known file format. In this dataset, extensions with a file count of less than 100 have been truncated to 6 characters or less, and files with no extension are not included.
This dataset will be updated on GitHub as new versions are available.
Up next
In my next post, I’ll talk about our iterative process of updating the Risk Matrix. Subscribe to this blog in the sidebar to see it in your inbox next week.
Exciting updates to the Digital Preservation Framework! The enhanced Risk Matrix and insights into file format extensions are valuable additions. Looking forward to the next posts in the series to dive deeper into the process and findings. Kudos to the team for the collaboration and detailed work!