This post was written by Hannah Wang, Senior Digital Preservation Specialist.
The NARA Digital Preservation Unit is very excited to announce that the most recent release of the Digital Preservation Framework is now available on GitHub. This release includes a major overhaul of the Risk Matrix, with new and updated questions about how we evaluate risk to file formats, as well as a new report on the file format extensions present in our holdings.
This blog post is the last in a four-part series about this major re-release. In the first post, I introduced the Framework. In the second post, I discussed what exactly has changed in this new release. In the third post, I discussed our process for updating the Risk Matrix.
We were lucky to work with the Public Affairs team at NARA to put together this article about the updates to the Framework; it’s a great high-level overview of this project and digital preservation at NARA. And if you want even more information about how we assess file format risk at NARA, you can check out our paper, co-written with our Library of Congress colleagues, that we presented at the International Conference on Digital Preservation in September.
Findings and takeaways from updating the Risk Matrix
Changed Risk Levels
As discussed previously on this blog, the Risk Matrix calculates an overall numeric Risk Rating that is used to assign a general Risk Level (Low Risk, Moderate Risk, and High Risk). When the Risk Matrix was originally created, the decision was made to distribute scores in this way:
- The lowest-scoring 10% of formats are considered High Risk
- The highest-scoring 25% of formats are considered Low Risk
- All formats that fall in between these thresholds are considered Moderate Risk
As we have added more formats over time, without changing the numeric thresholds for Low/Moderate/High Risk, this distribution has remained consistent:
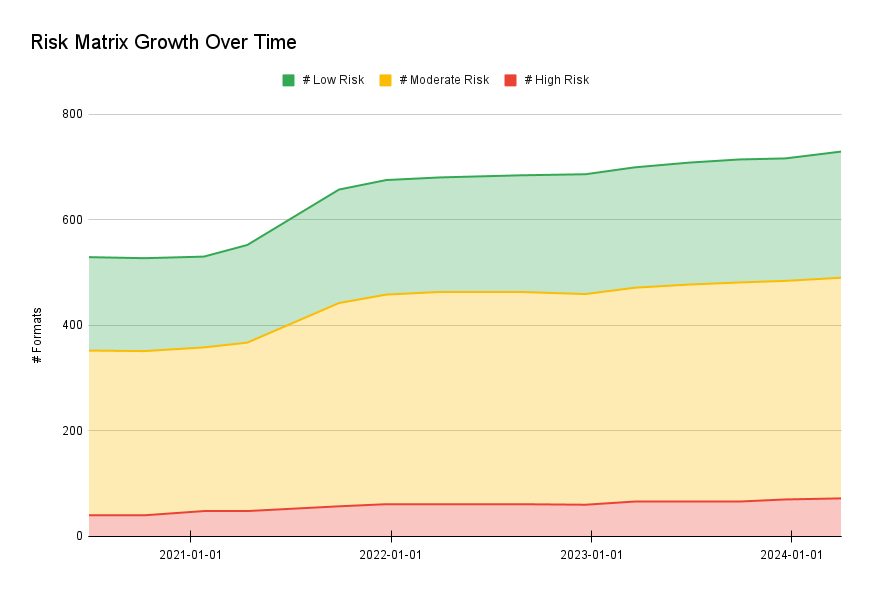
With new weights assigned to different questions, however, we needed to update the numeric thresholds for assigning formats to Low, Moderate, and High Risk Levels, while maintaining the same distribution as before.
After we updated these thresholds, there was quite a bit of movement between Risk Levels: 187 formats had their Risk Level changed.
Most of this movement was between adjacent categories:
- 69 formats changed from Low to Moderate Risk
- 26 formats changed from Moderate to Low Risk
- 46 formats changed from Moderate to High Risk
- 45 formats changed from High to Moderate Risk
Only one format had a more drastic change: NF00735 – ASP.NET HTTP Handler File. This is a compiled binary file format used by ASP.NET applications for handling embedded resource requests. Since we hadn’t anticipated seeing any file formats change Risk Level so dramatically, we took a closer look at this file format in the Risk Matrix. It appears that the Risk Level changed from Low to High for two reasons:
- There were some scoring errors for this format in the old version of the Risk Matrix, which were amended in the update.
- “Unknown” responses are now given a negative weight. In the old version of the Risk Matrix, an “Unknown” response would usually translate to a “0,” counting neither negatively nor positively towards the overall score. As a team, an early conclusion we reached in the Risk Matrix revisions process was that formats that are more “Unknown” pose just as great a risk as formats that are known to have multiple risk factors, because it is not possible to plan for and mitigate unknown risks. In the new Risk Matrix, we have reflected this fact by assigning negative scores to all “Unknown” responses. This means that formats like ASP.NET HTTP Handler File, for which there is limited documentation, answering “Unknown” to multiple questions will contribute negatively to the overall score.
These two factors weighed heavily in the rescoring process for many formats across the Risk Matrix; they are just most dramatically revealed in the new entry for this particular format.
Distribution of risk across format categories
Another interesting set of data is the distribution of Risk Levels across all format categories:
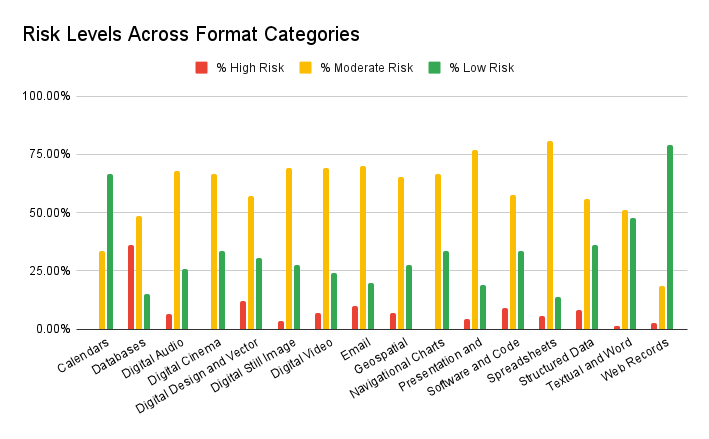
As you can see from the chart, the category with the highest percentage of High Risk formats is Databases. Without diving further into the data (for now), we can likely attribute this to the high percentage of older proprietary formats in this category for which little public documentation is available. It’s also possible that there are more software dependencies for these formats.
The category with the highest percentage of Low Risk formats is Web Records. Standing in direct opposition to Databases, this category has a large number of formats with open standards created for the web, as well as open web archiving standards.
There is definitely more data to dig into as we adjust to maintaining this new version of the Risk Matrix; let us know in the comments if you’re interested in us sharing more findings like these on the blog in the future.
Process takeaways
The process for rescoring the Risk Matrix was itself informative. For the first time, we divided up formats in the Risk Matrix by category, so each staff member became a “specialist” in particular categories and families of formats. This meant that it was easier to see commonalities and differences within categories of formats. It also meant that we could develop category-specific scoring guidance for each question.
For example, Question 6.5 asks: Is there software supported by current computing environments that can create the format? We developed guidance that says:
- For the Software and Code category, the “software” in this question refers to the compiler or interpreter.
- For the Digital Still Image category, the “software” in this question could refer to cameras, if applicable.
The process of community review, which I discussed in my last post, also made it clear that we should write more about our process for risk assessment and preservation planning. We plan to use this blog for that purpose.
Next steps
Since releasing these updates, our Digital Preservation staff has grown! One of the major next steps has been onboarding new staff to the Framework and the process of adding new formats. This gives us an opportunity to test the quality of our revision work with fresh eyes, as well as improve our documentation.
We will continue to maintain and grow the Framework, returning to our quarterly release schedule. You can expect a new release in December 2024. Since starting this blog series, we have also received a couple of feature requests relating to the Category Plans: namely, releasing them in Markdown (in addition to PDF) and releasing the Category Plan template for others to use. We’re happy to be getting feedback and requests from the community for these resources, and in both cases we are planning to incorporate these new features in the near future.
In the meantime, please subscribe and comment below!
Thank you Hannah for this thoughtful overview of the risk matrix and all the process surrounding it. It’s been a wonderful series to kick off this blog. I look forward to learning more! We always enjoy collaborating and learning from our NARA colleagues.